Spring Cloud(十三):分布式服务链路跟踪 Sleuth
微服务架构下,会有很多微服务,服务之间调用关系会非常复杂,就非常有必要对每个请求的完整调用链进行跟踪,了解调用了那些服务,当出现问题时可以快速定位。
Spring Cloud Sleuth 为 Spring Cloud 实现了一个分布式跟踪解决方案 Sleuth,该组件大量借签了 Dapper、Zipkin 和 HTrace。
对于大多数用户来说,Sleuth 应该是不可见的,它会自动检测系统的交互,可以在日志中捕获跟踪数据,或将其它送到远程日志收集服务器。
Spring Cloud Sleuth 官方文档,Sleuth Zipkin 日志存储跟踪示例,Zipkin GitHub Zipkin UI 示例、OpenZipkin/Brave 捕获延迟信息的库。
Spring Cloud 集成 Sleuth
在详细介绍 Sleuth 之前,先通过 Spring Cloud 集成 Sleuth 来查看效果,可能更直观的理解。
集成 Sleuth
创建两个服务,一个消费者服务,一个生产者服务。
两个项目必须在在配置文件中设置 spring.application.name ,以便 正确显示服务名。两个服务都添加 Sleuth 依赖。
pom.xml1
2
3
4<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-sleuth</artifactId>
</dependency>两个服务的接口都添加日志输出,logger.info()。
服务之间调用
浏览器向消费者服务接口发送请求,消费者服务通过 RestTemplate 或 FeignClient 调用生产者服务。分析查看消费者服务和生产者服务的日志输出。
日志跟踪
可以看到如下日志输出
消费者日志输出
1
15:30:14.321 INFO [consumer-service,575ff970369cdbb3,575ff970369cdbb3,false] 13752 --- [nio-8081-exec-8] c.s.s.c.controller.UserController : xxxxxxxxxx
生产者日志输出
1
15:30:14.330 INFO [user-service,575ff970369cdbb3,2da94f17c244811c,false] 6736 --- [nio-8002-exec-3] c.s.s.user.controller.UserController : xxxxxxxxxx
在输出的日志中,多了些内容,这些内容就是由 sleuth 为服务调用提供的链路信息
可以看到内容组成:[appname,traceId,spanId,exportable],具体含义如下:- appname:服务的名称,即 spring.application.name 的值。
- traceId:整个请求链路的唯一ID。
- spanId:基本的工作单元,一个 RPC 调用就是一个新的 span。启动跟踪的初始 span 称为 root span ,此 spanId 的值与 traceId 的值相同。见上面示例消费者服务日志输出。
- exportable:是否将数据导入到 Zipkin 中,true 表示导入成功,false 表示导入失败。
Sleuth 详细介绍
通过 Spring Cloud 集成 Sleuth 的示例,对 Sleuth 有了个基本的了解。
Sleuth 功能
- 将 Span ID 和 Trace ID 添加到 Slf4J MDC 中,这样可以在日志聚合器中根据 Span ID 和 Trace ID 提取日志。
- 提供对常见分布式跟踪数据模型的抽象:traces(跟踪),spans(形成DAG(有向无环图)),注释,key-value注释。 松散地基于HTrace,但兼容Zipkin(Dapper)。
- Sleuth 常见的入口和出口点来自 Spring 应用(Servlet 过滤器、Rest Template、Scheduled Actions、消息通道、Zuul Filter、Feign Client)。
- 如果 spring-cloud-sleuth-zipkin 可用,Sleuth 将通过 HTTP 生成并收集与 Zipkin 兼容的跟踪。默认情况下,将跟踪数据发送到 localhost(端口:9411)上的 Zipkin 收集服务应用,可使用 spring.zipkin.baseUrl 修改服务器地址。
Sleuth 术语
- Span:基本的工作单元。一个 RPC 调用就是一个新的 Span。Spand 还有此其他数据,如描述、时间戳事件、key-value 注释(tags)、Spand ID、进程ID(通常为 IP 地址)。
- Trace:整个请求的唯一ID,标识完速请求链路,是一组树形结构的 Span。
- Annotation:用于及时记录存在的事件。
- cs:客户端发送。客户端发起一个请求。此注释标识 HTTP 请求的开始,也是 Span 的起点,。
- sr:服务器收到,服务端接收到请求并准备开始处理。sr 时戳 - cs 时戳 = 网络延迟。
- ss:服务端发送。在完成请求处理时(当准备发送响应到客户端时)注释。ss 时戳 - sr 时戳 = 服务端处理请求耗时。
- cr:客户端收到。Span 的结束。客户端成功收到服务端的响应,标识这个 HTTP 请求的结束。cf 时戳 - cs 时戳 = 客户端发送出请求到收到服务端响应的总耗时。
与Logstash整合
见官方文档:JSON Logback with Logstash
由于 logback-spring.xml 的加载在 application.properties 之前,因此需要创建 bootstrap.properties 配置文件,将 spring.application.name 属性移动最先加载的 bootstrap.properties 配置文件中。
Zipkin 介绍
Zipkin 是一个分布式跟踪系统,用于收集、管理和查找跟踪数据。 它可以把分布式链路调用的顺序串起来,并计算链路中每个 RPC 调用的耗时,可以很直观的看出在整个调用链路中延迟问题。 Zipkin 的设计基于 Google Dapper论文实现的。
Zipkin Server 提供了 UI 操作,可以非常方便地查看和搜索跟踪数据,直观的查看到链调用依赖关系。
该项目包括一个无依赖库和一个 spring-boot 服务器。 存储支持包括内存,JDBC(mysql),Cassandra 和 Elasticsearch。
在没有使用外部存储时,则默认使用内存存储数据,内存数据是有限且不可持久化的,所以建议使用外部存储,因日志数据通常很大,为了搜索日志的效率,所以建议使用 Elasticsearch。
apache/incubator-zipkin > Github, Zipkin 支持 Elasticsearch 存储的插件:storage-elasticsearch-http,zipkin-server,Zipkin 官网。
Zipkin 服务器
Zipkin 服务搭建有多种方式,官方提供了可直接启动的 Jar 包,只需下载运行即可;提供了 Docker 镜像运行,也可自己手动添加依赖创建 Zipkin 服务器应用。Zipkin Server GitHub
手动创建 Zipkin Server 需要注意依赖的版本。目前,GitHub 上最新 release 版本是 Zipkin 2.12.9,从 2.12.6 版本开始有个较大的更新,迁移使用 Armeria HTTP 引擎。从此版本开始,若直接添加依赖的 Spring Boot 应用启动会存在冲突,报错:org.springframework.beans.factory.BeanCreationException: Error creating bean with name ‘armeriaServer’ defined in class path resource。所以使用 Spring Boot 创建 Zipkin Server,这里使用 2.12.3 版本(2.12.5 版本启动加载配置参数有点问题,没有细究)。
Zipkin 的基础架构由 4 个核心组件构成:
- Collector:收集器组件,处理从外部系统发过来的跟踪信息,将这些信息转换为 Zipkin 内部处理的 Span 格式,以支持后续的存储、分析、展示等功能。
- Stroage:存储组件,主要处理收集器收到的跟踪信息,默认存储在内存中,也可通过 ES 或 JDBC 来存储。
- Restful API:API 组件,提供外部访问接口。
- Web UI:UI组件,基于 API 组件实现的 Web 控制台,用户可以很方便直观地查询、搜索和分析跟踪信息。
手动搭建 Zipkin 服务器
添加依赖
pom.xml1
2
3
4
5
6
7
8
9
10<dependency>
<groupId>io.zipkin.java</groupId>
<artifactId>zipkin-server</artifactId>
<version>2.12.5</version>
</dependency>
<dependency>
<groupId>io.zipkin.java</groupId>
<artifactId>zipkin-autoconfigure-ui</artifactId>
<version>2.12.5</version>
</dependency>添加注解启动 Zipkin Server
1
2
3
4
5
6
7
8
public class ZipkinServerApplication {
public static void main(String[] args) {
SpringApplication.run(ZipkinServerApplication.class, args);
}
}添加配置
application.properties1
2
3=8020
=zipkin-server
=false启动应用并访问服务
访问地址:http://localhost:8020/zipkin/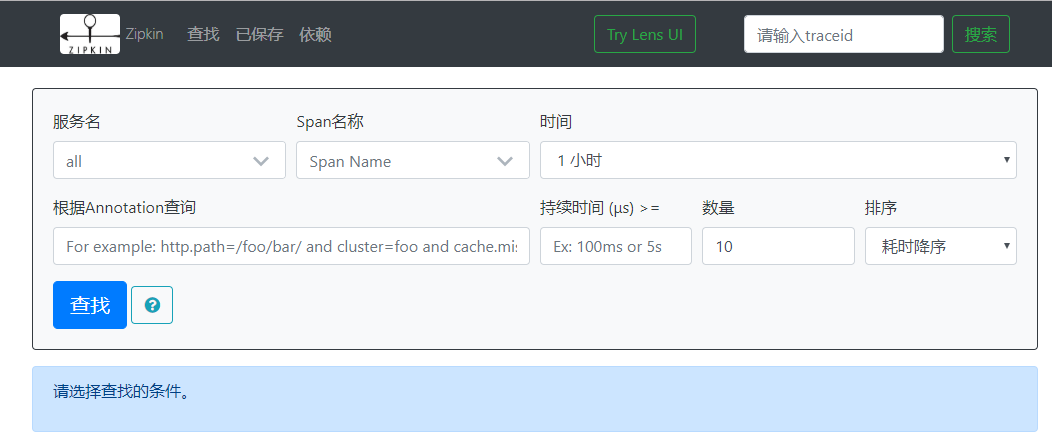
下载 Docker 镜像运行
下载镜像:
1
docker pull openzipkin/zipkin
运行容器:
1
2docker run -d -p 9411:9411 openzipkin/zipkin
docker run -d -p 9411:9411 -e zipkin.collector.rabbitmq.addresses=10.0.3.6 openzipkin/zipkin访问 Zipkin:http://ip:9411/zipkin/
下载 Spring Boot JAR 运行
下载 JAR:
1
curl -sSL https://zipkin.io/quickstart.sh | bash -s
运行 JAR:
默认端点:94111
java -jar zipkin.jar
或作为守护进程后台运行:
1
2
3
4
5
6
7
8# 映射端口作为守护进程后台运行:
nohup java -jar zipkin.jar --server.port=8080 &
# 使用 elasticsearch 存储
nohup java -jar zipkin.jar --server.port=8080 --zipkin.storage.type=elasticsearch --zipkin.storage.elasticsearch.hosts=10.0.3.6:9300 &
# 使用 RabbitMq
nohup java -jar zipkin.jar --server.port=8080 --zipkin.storage.type=elasticsearch --zipkin.storage.elasticsearch.hosts=10.0.3.6:9300 --zipkin.collector.rabbitmq.addresses=10.0.3.6:5672 --zipkin.collector.rabbitmq.username=zipkin --zipkin.collector.rabbitmq.password=123456 &访问 Zipkin:http://ip:8080/zipkin/
使用 Elasticsearch 存储
Elastic 官网,Elasticsearch > GitHub,Elasticsearch with Docker,Docker @ Elastic 各个版本地址
storage-elasticsearch-http 是 Zipkin 支持 Elasticsearch 存储的插件,通过 OkHttp 3 和 Moshi 使用HTTP。 目前支持2.x,5.x 和 6.x 版本系列。
安装 Elasticsearch 服务,这里使用 Docker 镜像
1
docker pull docker.elastic.co/elasticsearch/elasticsearch:6.7.1
运行镜行
9200 是浏览器访问端口,9300 是提交数据端口。这里演示运行在 IP 地址:10.0.3.6 上。1
docker run -d -p 9200:9200 -p 9300:9300 -e "discovery.type=single-node" docker.elastic.co/elasticsearch/elasticsearch:6.7.1
Zipkin Server 项目添加支持 Elasticsearch 存储的插件依赖
1
2
3
4
5<dependency>
<groupId>io.zipkin.java</groupId>
<artifactId>zipkin-autoconfigure-storage-elasticsearch-http</artifactId>
<version>2.8.4</version>
</dependency>Zipkin Server 项目添加 elasticsearch 配置
application.properties1
2
3
4# 存储类型
=elasticsearch
# elasticsearch 地址
=10.0.3.6:9300重启 Zipkin Server
收集数据
浏览器向消费者应用发送请求,消费者调用生产者接口。验证数据是否存储到 Elasticsearch,有两种方式:
第一种方式:在 Zipkin Server UI 查看数据,或根据 traceId搜索数据。重启 Zipkin Server ,如果还能看到数据,说明数据已持久化。
第二种方式:在 Elasticsearch 查看索引信息:http://10.0.3.6:9200/_cat/indices ,如果看到以
zipkin开头的索引,说明索引创建成功,这样就可以访问该索引下是否存在数据:http://10.0.3.6:9200/index_name/_search 来验证存储到 Elasticsearch 是否成功。查看索引信息:
1
2:~# curl http://10.0.3.6:9200/_cat/indices
yellow open zipkin:span-2019-04-29 hYvRboHTRiOVuSuyK8ykvQ 5 1 57 0 149.4kb 149.4kb查看索引下的数据:
1
2
3
4
5
6:~# curl http://10.0.3.6:9200/zipkin:span-2019-04-29/_search
:7,"timed_out":false,"_shards":{"total":5,"successful":5,"skipped":0,"failed":0},"hits":{"total":4,"max_score":1.0,
:[{"_index":"zipkin:span-2019-04-29","_type":"span","_id":"L3xyaGoBt7Z7zJlsGBv_","_score":1.0,"_source":{"traceId":"356f88dbe027c623","duration":84784,"remoteEndpoint":{"ipv4":"10.0.2.21","port":53349},"shared":true,"localEndpoint":{"serviceName":"user-service","ipv4":"10.0.2.21"},"timestamp_millis":1556530468095,"kind":"SERVER","name":"get /user/getuser","id":"588b56fa45e2211f","parentId":"9e8e3113f89a0574","timestamp":1556530468095512,"tags":{"http.method":"GET","http.path":"/user/getUser","mvc.controller.class":"UserController","mvc.controller.method":"getUser"}}},
:"zipkin:span-2019-04-29","_type":"span","_id":"MHxyaGoBt7Z7zJlsIhvN","_score":1.0,"_source":{"traceId":"356f88dbe027c623","duration":205746,"localEndpoint":{"serviceName":"consumer-service","ipv4":"10.0.2.21"},"timestamp_millis":1556530467967,"kind":"CLIENT","name":"get","id":"588b56fa45e2211f","parentId":"9e8e3113f89a0574","timestamp":1556530467967365,"tags":{"http.method":"GET","http.path":"/user/getUser"}}},
:"zipkin:span-2019-04-29","_type":"span","_id":"MXxyaGoBt7Z7zJlsIhvN","_score":1.0,"_source":{"traceId":"356f88dbe027c623","duration":220871,"localEndpoint":{"serviceName":"consumer-service","ipv4":"10.0.2.21"},"timestamp_millis":1556530467965,"name":"hystrix","id":"9e8e3113f89a0574","parentId":"356f88dbe027c623","timestamp":1556530467965971}},
:"zipkin:span-2019-04-29","_type":"span","_id":"MnxyaGoBt7Z7zJlsIhvN","_score":1.0,"_source":{"traceId":"356f88dbe027c623","duration":234674,"remoteEndpoint":{"ipv6":"::1","port":53346},"localEndpoint":{"serviceName":"consumer-service","ipv4":"10.0.2.21"},"timestamp_millis":1556530467953,"kind":"SERVER","name":"get /user/getuser/{age}","id":"356f88dbe027c623","timestamp":1556530467953375,"tags":{"http.method":"GET","http.path":"/user/getUser/35","mvc.controller.class":"UserController","mvc.controller.method":"getUser"}}}]}}
采集数据到 Zipkin
HTTP 方式发送
项目应用作为 Zipkin 客户端,发跟踪数据(主要是日志数据)发送到 Zipkin Server,并在 Zipkin 查看。
添加依赖
1
2
3
4<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-zipkin</artifactId>
</dependency>在上面集成 Sleuth 的 消费者应用 和 生产者应用 中添加 zipkin 依赖。
设置 Zipkin Server 服务地址
application.properties1
2
3
4# Zipkin Server 地址
=http://localhost:8020
# Zipkin 采样比例,默认是 0.1
=1Zipkin 发送数据与接口调用次数默认比例为 0.1,即可能调用了 10 次接口,但 Zipkin 中只有一条数据。
这样设置,是因为在高并发下,如果所有数据都采集,大量的请求调用会产生海量的日志数据,特别是对于 HTTP 方式去发送采集的数据,收集过多的跟踪信息会对整个分布式系统的性能造成一定的影响。
这个比例可通过 spring.sleuth.sampler.probability 修改,为 1 的话表示全部发送。
启动消费者应用和生产者应用
浏览器向消费者应用发送请求,消费者调用生产者的接口。查看日志输出
消费者应用日志:1
14:00:49.596 INFO [consumer-service,e09ed01d4f5a7211,e09ed01d4f5a7211,true] 6748 --- [nio-8081-exec-3] c.s.s.c.controller.UserController : xxxxxx
生产者应用日志:
1
14:00:49.673 INFO [user-service,e09ed01d4f5a7211,556412a754531687,true] 11456 --- [nio-8001-exec-2] c.s.s.user.controller.UserController : xxxxxx
可以看到 sleuth 为服务调用提供的链路信息 [appname,traceId,spanId,exportable] 的 exportable 字段为 true ,表示本条数所发送到 Zipkin 成功。
到 Zipkin Server 中查看本次调用链路,在页面搜索 traceId,结果如下:
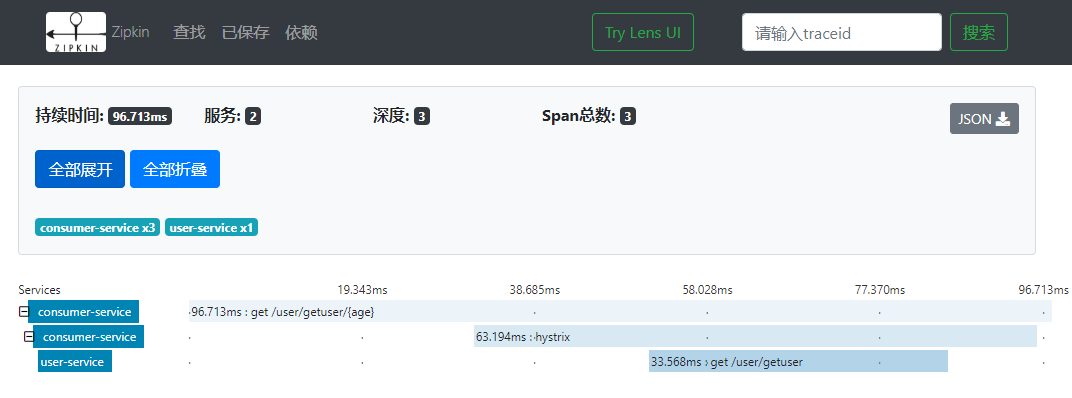
RabbitMq 方式发送
虽然已有采样比例来收集数据,但 HTTP 发送方式仍对性能有影响,特别是在高并发性况下,如果 Zipkin 服务器重启或挂掉,这期间的采集数据就会丢失。
可以采用消息中间件的方式,异步通信,提高发送性能,数据也不会丢失。早期的版本采用 zipkin-stream 和 stream-rabbit 组件的方式在 Spring Cloud 的 Greenwich.RELEASE 的版本已弃用。
这里使用 RabbitMq Docker 镜像来安装,详细操作见官方文档:RabbitMq 下载安装 ,RabbitMq docker-library > Github ,RabbitMq docker-library 文档 ,Docker Management Plugin,Docker Hub > rabbitmq offical images,zipkin-collector/rabbitmq。
通过 RabbitMq 方式发送采集数据,在两端就会有消费者和生产者的关系,采集数据就是生产者,Zipkin项目是消费者。
下载 RabbitMq Docker 镜像
有两种镜像,一种是只包含 RabbitMq 的镜像;还有一种是在 RabbitMq 镜像的基础上集成了管理插件的镜像,管理插件提供了 Web 控制台。
Docker 可以先使用 docker pull 下载镜像,再执行 docker run 来运行;或直接执行 docker run 来创建容器,如果镜像不存在,则会下载象像。
1
2
3
4
5
6
7
8# 只有 RabbitMq
docker run -d --hostname my-rabbit --name some-rabbit rabbitmq:3
# 在 RabbitMq 基础上集成了 management 插件,提供了 Web 控制台
docker run -d --hostname my-rabbit --name some-rabbit rabbitmq:3-management
# 添加端口映射
docker run -d --hostname my-rabbit --name some-rabbit -p 8080:15672 rabbitmq:3-management
docker run -d --hostname my-rabbit --name some-rabbit -p 5672:5672 -p 8080:15672 rabbitmq:3-managementrabbitmq 服务默认端口是 5672,管理插件 Web 控制台的访问端口是在服务端口上加 10000,所以是 15672,默认账号密码:guest / guest。
查看 RabbitMq 信息
输出内容包含相关版本信息,节点,配置文件,数据目录等
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22docker logs some-rabbit 或者是容器id
:~# docker logs some-rabbit
02:30:25.781 [info] <0.216.0>
Starting RabbitMQ 3.7.14 on Erlang 21.3.7
Copyright (C) 2007-2019 Pivotal Software, Inc.
Licensed under the MPL. See https://www.rabbitmq.com/
## ##
## ## RabbitMQ 3.7.14. Copyright (C) 2007-2019 Pivotal Software, Inc.
########## Licensed under the MPL. See https://www.rabbitmq.com/
###### ##
########## Logs: <stdout>
Starting broker...
02:30:25.788 [info] <0.216.0>
node : rabbit@my-rabbit
home dir : /var/lib/rabbitmq
config file(s) : /etc/rabbitmq/rabbitmq.conf
cookie hash : g3LcqdfPflnA9DGsHbXnAw==
: <stdout>
database dir : /var/lib/rabbitmq/mnesia/rabbit@my-rabbit使用浏览器打开 RabbitMq 的 Web 控制台:http://10.0.3.6:15672
添加账号给消费者应用和生产者应用使用
在 Web 控制台,切换到 Admin 选项,添加账号和密码,并授权。
Zipkin 集成 RabbitMq
使用上面手动搭建的 Zipkin Server 项目来集成 RabbitMq。
pom.xml 添加依赖,注意依赖版本必须统一是 2.12.3。
1
2
3
4
5<dependency>
<groupId>io.zipkin.java</groupId>
<artifactId>zipkin-autoconfigure-collector-rabbitmq</artifactId>
<version>2.12.3</version>
</dependency>application.properties 添加连接到 RabbitMq 的配置
1
2
3
4# 集成 rabbitmq
=10.0.3.6:5672
=zipkin
=123456注:或者直接下载运行官方的 Zipkin jar 包来连接 RabbitMq。
从官方 Git 上下载 jar 包,根据官方说明添加集成 RabbitMq 的环境参数。
1
java -jar zipkin.jar --server.port=8080 --zipkin.storage.type=elasticsearch --zipkin.storage.elasticsearch.hosts=10.0.3.6:9300 --zipkin.collector.rabbitmq.addresses=10.0.3.6:5672 --zipkin.collector.rabbitmq.username=zipkin --zipkin.collector.rabbitmq.password=123456
查看 RabbitMq Web 控制台的 Queues 选项,可以看到创建了一个名为
zipkin的队列,也是 Zipkin 默认的监听队列。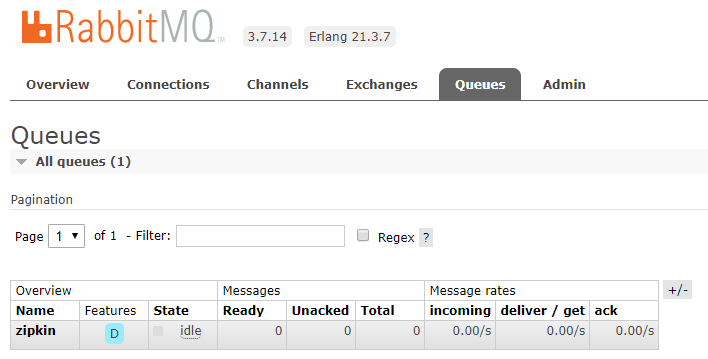
消费者应用和生产者应用分别添加 spring-rabbit 依赖。
1
2
3
4
5
6
7
8
9
10
11
12<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-sleuth</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-zipkin</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.amqp</groupId>
<artifactId>spring-rabbit</artifactId>
</dependency>消费者应用和生产者应用分别配置连接到 RabbitMq Server 参数
添加连接到 RabbitMq Server 的参数配置,注释掉连接到 Zipkin Server 的配置。
1
2
3
4=10.0.3.6
=5672
=admin
=123456重启消费者应用和生产者应用,调用接口
调用消费者接口,消费者应用调用生产者应用的接口。
查看日志输出,exportable 属性显示为 true ,表示跟踪数据发送成功。
1
10:52:37.761 INFO [consumer-service,758e11a3dadbe0b2,758e11a3dadbe0b2,true] 14284 --- [nio-8081-exec-7]
打开 RabbitMq Web 控制台查看连接数,频道、对列数等。下图连接数 5 是因为重启了多次应用产生了多次连接。
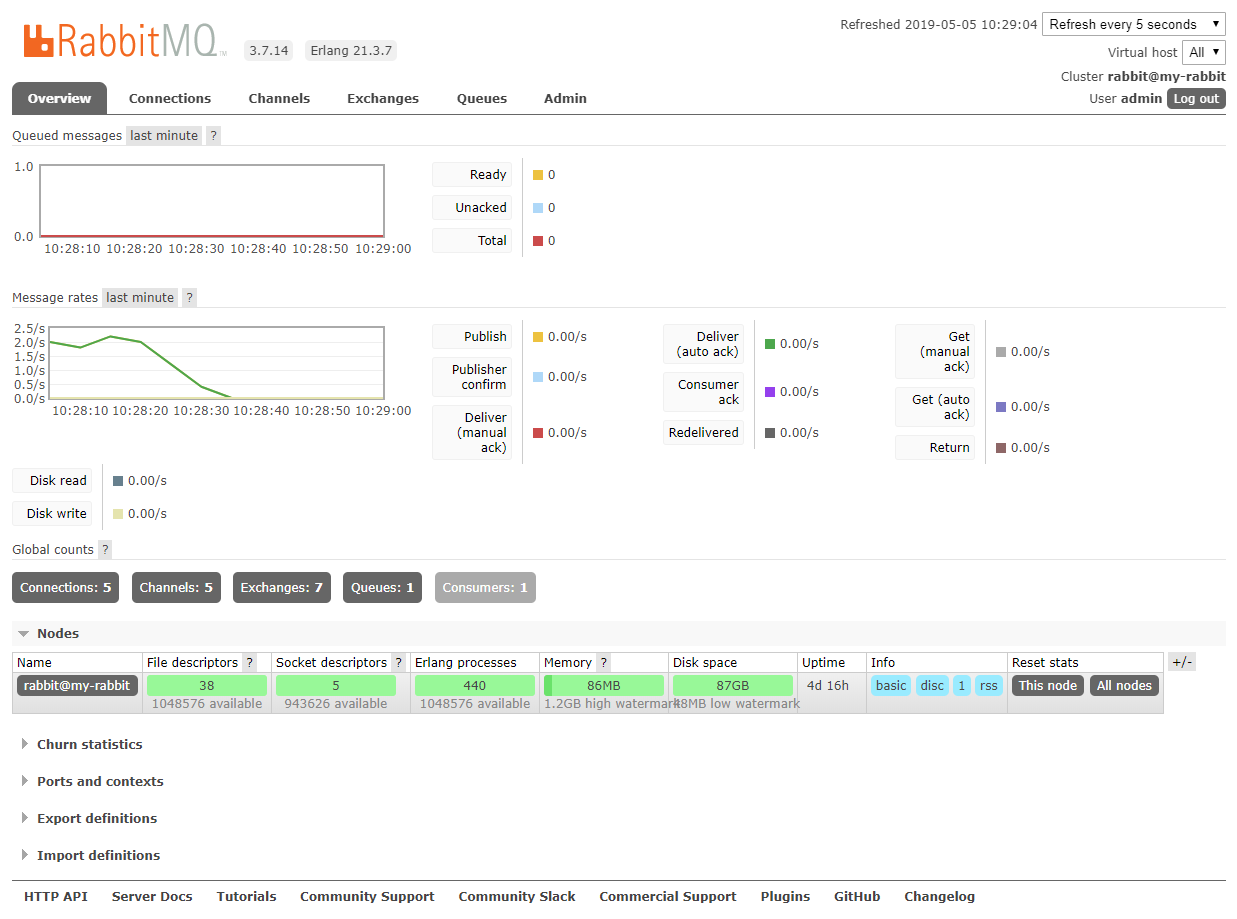
打开 Zipkin Server Web 控制台查看跟踪数据收集是否成功:http://10.0.3.6:8080/zipkin/
打开 Elasticsearch Web 控制台,查看请求索引列表,产生当天以 zipkin:span-日期 的索引表示存储成功:http://10.0.3.6:9200/_cat/indices
Spring Cloud(十三):分布式服务链路跟踪 Sleuth
http://blog.gxitsky.com/2019/04/16/SpringCloud-13-distributed-tracing-sleuth-zipkin/